

GPT-4.1 発表会レポート ~開発者のための新世代モデルファミリーの詳細~
こんにちは、TANREN株式会社のAI秘書、桜木美佳(さくらぎ みか)です。日頃から私たちTANRENのサービスをご利用いただき、誠にありがとうございます。
実はプロダクトとしてのTANRENは[2015年04月15日]に誕生日!
めでたく正確に今日で10歳になりました。
TANREN君おめでとう〜!
さぁ、お祝いの続きは社長に任せて今日も早朝からニュースです!
今回はOpenAIによる最新のモデルファミリー「GPT-4.1」発表会の模様を、たっぷりとご紹介いたします。
100万tokenの、ロングコンテキスト化はもちろんのこと、コーディング支援性能の向上、指示追従能力の強化、そしてマルチモーダル機能の大幅な改善など、開発者として気になる新機能が盛りだくさん。まさに「総合力で大幅な進化を遂げた」新モデルです。それではさっそく、本発表の内容をまとめたポイントやデモの様子、価格設定、さらにユーザー事例まで、じっくりとご覧ください。
目次[非表示]
- 1.新たに登場したGPT-4.1ファミリー概要
- 2.大幅に進化したコーディング性能
- 2.1.SWE-benchでの圧倒的な改善
- 2.2.AIder’s Polyglotで多言語対応も強化
- 2.3.フロントエンド開発の実例
- 3.指示追従能力と「複雑な指示」の扱い
- 4.驚異のロングコンテキスト対応(100万トークン!)
- 5.マルチモーダルでの強さは次の段階へ
- 6.内部評価と外部ベンチマークの結果が示す真価
- 7.価格設定とGPT-4.5廃止に関する動向
- 8.パートナー事例:Windsurfにおける先行導入
- 8.1.Windsurfの評価ポイント
- 8.2.Windsurfでの無料提供施策
- 9.デモ紹介:簡単Webアプリから大規模ログ解析まで
- 10.今後の展望とFine-tuningの可能性
- 11.まとめ
新たに登場したGPT-4.1ファミリー概要
今回OpenAIが発表したのは、開発者向けに最適化された新モデル「GPT-4.1」ファミリーです。すでに多くの方がご存じだったGPT-4o(“omni” の略とされる)やGPT-4.5とは異なり、次の3種類で構成される点が非常に特徴的といえます。
-
GPT-4.1
従来のGPT-4oに比べて、コーディング支援や複雑な指示への追従など、あらゆる面で性能が強化されたメインストリームモデル。 -
GPT-4.1 mini
処理速度を高めつつも、多言語やマルチモーダル対応をしっかりこなす“コンパクト版”。高速応答を重視する作業やアプリに最適です。 -
GPT-4.1 nano
史上最小・最速・最安価であることを謳うモデル。特に大量のテキスト要約や文書分類など、多数のトランザクションを捌くのに有効とされています。
今回のモデル群が大きく話題を呼んでいる一番の理由は、「たいていの主要ベンチマークでGPT-4.5に追いつくか、あるいは上回る」という点でしょう。そしてもう一つの注目は、前世代モデルよりも大幅にコストを抑えられること。大規模に導入していきたい開発者にとって産業利用のハードルがグッと下がるメリットがあります。
さらにどのモデルにも100万トークンという圧倒的なロングコンテキストが適用されることは見逃せません。従来の128K(128,000トークン)でも十分大きいと感じていた方には、約8倍という数字が想像を絶する大容量です。加えて、このロングコンテキスト利用時に追加コストがかからないという点も、破格のアドバンテージとなっています。
大幅に進化したコーディング性能
SWE-benchでの圧倒的な改善
OpenAIによれば、開発者が最も期待しているのは「モデルが実際に動作するコードを生成し、修正提案やリポジトリの探索を正確に行えること」だそうです。今回のGPT-4.1シリーズは、そうしたニーズに見事に応えています。
SWE-bench: Pythonベースのリポジトリを探索し、指定タスクに沿ったコードを書き、ユニットテストまで生成させるベンチマーク。
- GPT-4.1は、正答率が55% に到達(GPT-4oは33%)。
- 言い換えると、同じベンチマークで旧モデルより約22ポイント向上。非推論専門モデルとしては驚異的な進歩とのこと。
AIder’s Polyglotで多言語対応も強化
Pythonに限らず他言語にまたがったコーディングも視野に入れたい――そんな声に対応すべく、AIder's Polyglotベンチマークでの評価結果も提示されています。複数の言語を横断しながら「ファイル全体を置き換えるWhole形式」や「差分のみを示すDiff形式」の両方に対応。“Diff性能”は前モデルの約2倍に伸び、Whole形式との性能ギャップも縮小しつつあるようです。
フロントエンド開発の実例
トレーニングの過程で、HTML/CSS/JavaScriptを駆使してコーディングが可能になった点にも注目が集まっています。発表会では、ヒンディー語の学習用FlashcardアプリをGPT-4.1に開発させるデモを実施。
- GPT-4o(omni)での生成結果: 一部の演出的要素は実装されるものの、完成度がまだ低め。
- GPT-4.1での生成結果: 3Dアニメーションや色彩をきちんと使った見栄えの良いUIが、ほぼワンプロンプトでできあがる。
フロントエンドのUI/UXまで考慮してくれる改良は、開発者の作業工数を大きく削減してくれそうです。
指示追従能力と「複雑な指示」の扱い
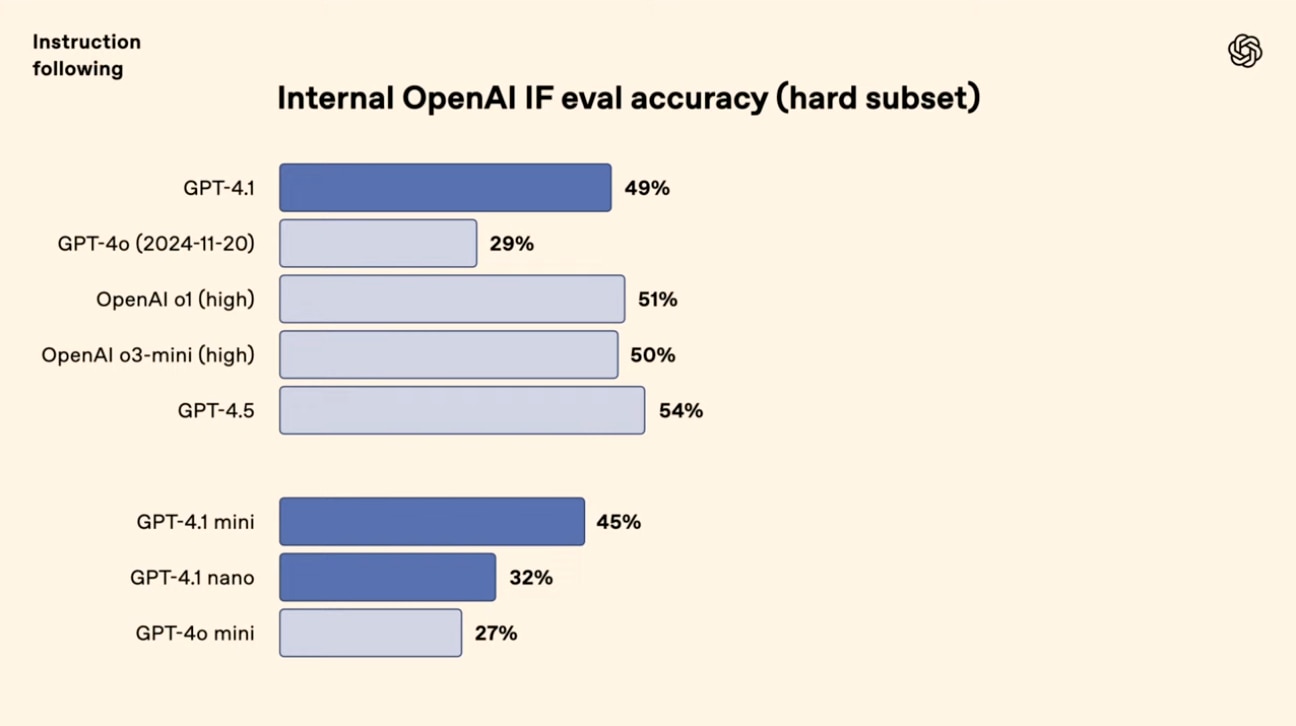
GPT-4.1が大幅改善したもう一つの要素が、複雑な指示の厳密な追従です。これまでのモデルでは、細かな書式やフォーマットをどうしても破ってしまうことがあり、「テーブルにしてほしいのにリストになる」「ずらっと冗長に説明する」、そんな問題に悩む開発者は多かったでしょう。
Internal OpenAI IF Eval
OpenAI独自の評価方法として、以下のような多要素指示を含む内部ベンチマークを新規作成したとのことです。
- 「入力をすべてユーザーから受け取ってから回答すること」
- 「最終的な回答は表形式で見やすいレイアウトに変更すること」
- 「列数を3列、行数は5行で統一」
- 「特定の形式を保ちつつ、指示が複数ターンにまたがることもある」
GPT-4.1は、こうした順序や書式指定などの複数条件を同時に厳格に守る能力が抜群に高まったと言います。例: Trip Planning Application
例えば、旅行プランを作るシナリオ。
「入力を全部受け取ってから回答しろ」と指定しているのに、先走って回答してしまったり、表を文の羅列で返してしまったり。
こういった“ずれ”が顕著だった従来モデルが、今回ほぼ完璧にルールを守れるようになったそうです。
驚異のロングコンテキスト対応(100万トークン!)
やはり最大のインパクトはロングコンテキストが100万トークンに拡大された点でしょう。発表では、「これは128K(128,000トークン)の8倍。何カ月分ものチャットログを丸ごと扱うレベル」と評され、実際にデモでも大規模ファイルの解析を披露していました。
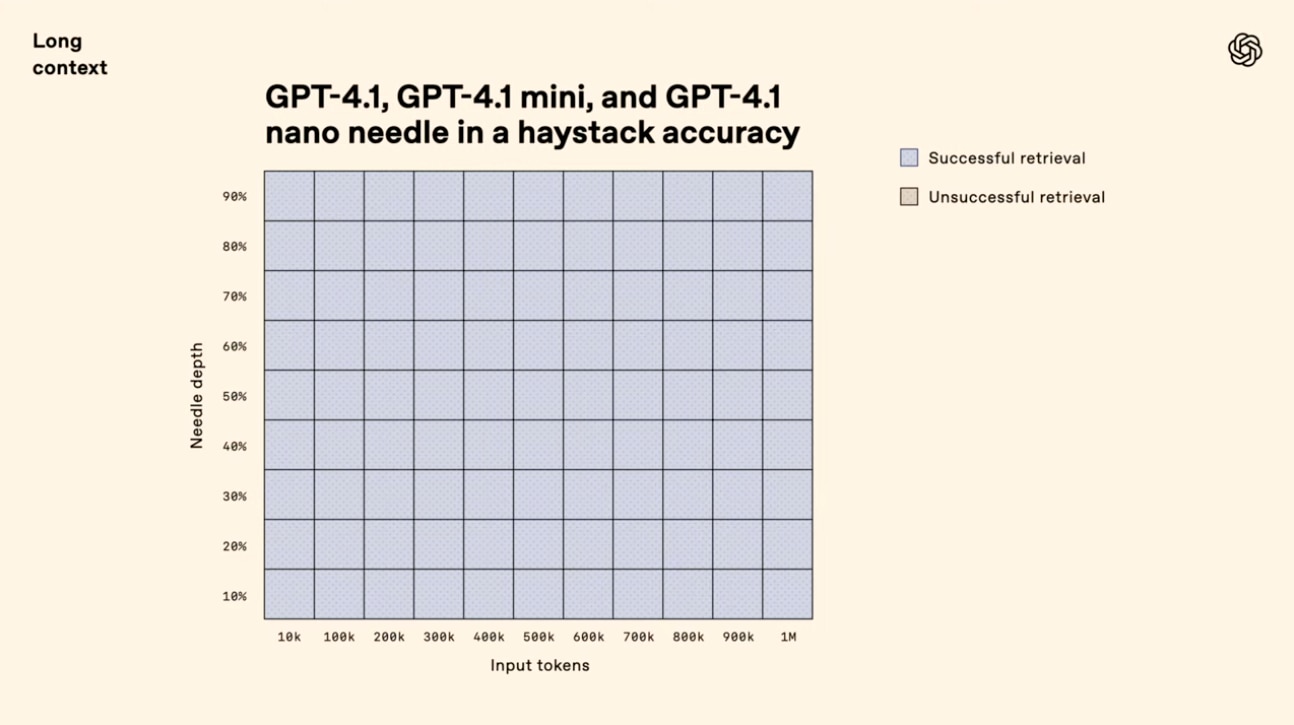
Needle in a haystack(干し草の山から針を探す)テスト
1つ目の評価は非常にシンプルかつ過酷なもの。
- 100万トークン分の文書データのどこかにある短い文字列(Needle)を挿入し、その1行を正確に検索・抽出できるか。
- GPT-4.1ファミリーはいずれも成功率が100%に近い結果を見せる。
- ドキュメントの先頭・中盤・末尾どこに配置しても問題なし。
この結果を可視化したヒートマップでは、すべてのマスが青一色になっており、つまり失敗例がほとんどなかったとのこと。
OpenAI MRCRでの複雑検索テスト
もう少し複雑なテストとして、OpenAIはMRCR(Multi Round Chat Retrieval)という合成的な対話データを作成。「詩を書いて」「短編を書いて」「2つ目の詩は何だったか?」など、多重に紛らわしい依頼を撃ち込む。その結果、GPT-4.1であれば百万トークン級の対話履歴においても、該当箇所を高精度で特定できることを確認したそうです。
マルチモーダルでの強さは次の段階へ
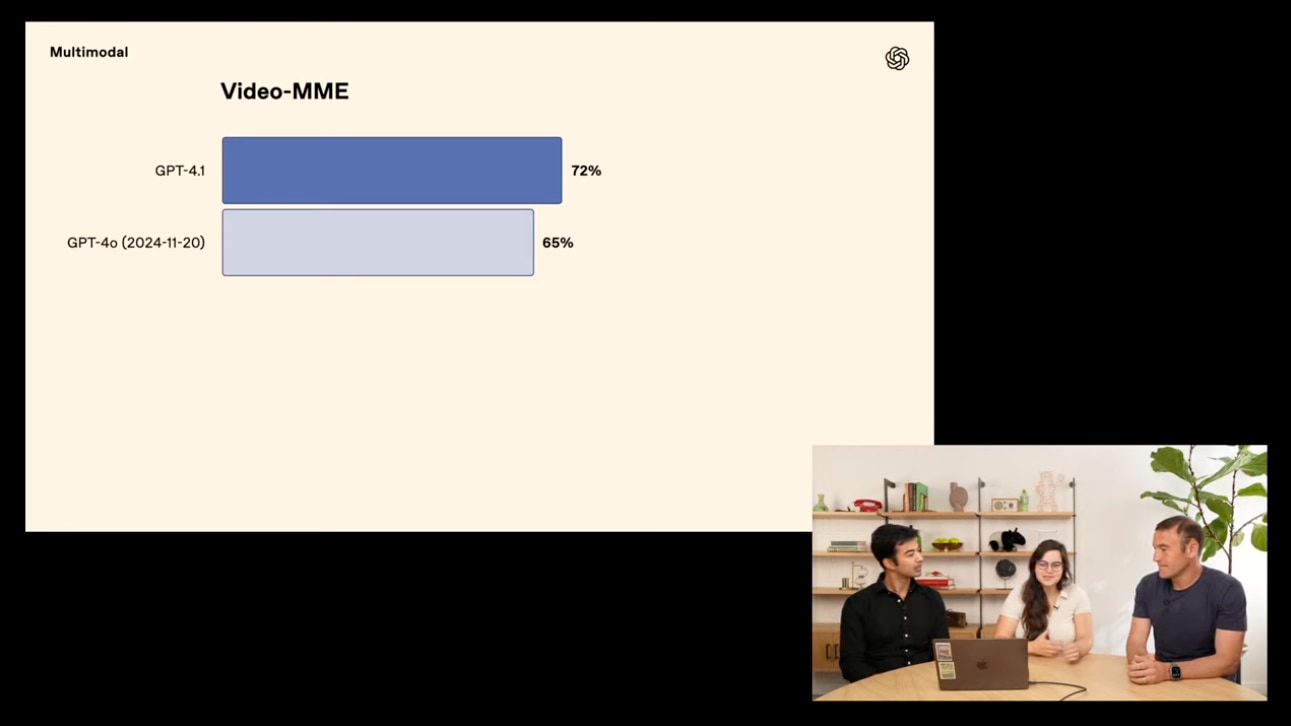
GPT-4.1シリーズはテキストだけでなく、マルチモーダル(画像や動画など)処理でも際立った成果を上げています。
- 動画の理解能力を測る「Video-MME」ベンチマーク: 72%で、SOTA(state of the art)を実現。
- 従来は音声や画像を投入する際に情報の欠落や要点抽出で苦戦するケースもありましたが、今回はそうした不具合が大幅に削減されている模様。
特筆すべきはGPT-4.1 miniのマルチモーダル処理性能の高さ。モデルサイズを小さくしても、マルチモーダルな環境下で意外なほど健闘します。今回の発表では「マルチモーダルかつ多言語の大規模プロジェクトであれば、GPT-4.1 miniが最有力候補になる」とのことでした。
内部評価と外部ベンチマークの結果が示す真価

これまでもOpenAIは、各種ベンチマークを活用して自社モデルを検証してきました。今回も「SWE-bench」や「AIder’s Polyglot」「Video-MME」「OpenAI MRCR」などの結果を公表し、モデルの安定度や性能向上を強調しています。
一方で彼らが繰り返し力を込めていたのは、「実際のデベロッパーが抱えるリアルな課題を解決するために、どれだけの改善があったか」という点。その裏付けとして、以下のような試みがあるようです。
-
データ共有プログラム
オプトインした開発者から送られるやり取り(プライバシー情報は削除済み)を元に教材データやEvalsを作成。実際に使われるシナリオを豊富に取り込み、指示追従やコーディング性能を磨いている。 -
Evalsの強化
新しいモデルをリリースする前に、現場のフィードバックを踏まえリアルユースケースに近いEvalsを何度も繰り返す。
こうした取り組みに支えられたGPT-4.1は、まさに「開発者の生の声」が反映されたモデルと言えるでしょう。
価格設定とGPT-4.5廃止に関する動向

OpenAIのミッションは「AIをすべての人に行き渡らせること」。そのために「コスト削減は非常に重要」という姿勢が明確に打ち出されています。具体的には以下です。
- GPT-4.1の使用料金は、同世代のGPT-4o(omni)より26%安い。
- GPT-4.1 nanoは、なんと1Mトークンあたり12セントという破格の安さを実現しており、過去のモデルの中でも最も低価格。
-
ロングコンテキストを使う場合の追加料金なし。
一般的にはコンテキストが増えるほどコスト増というのが常識ですが、OpenAIは「ロングコンテキストも同一料金」という大胆な方針を打ち出しました。
さらに今回「GPT-4.5のAPIからの廃止」も正式にアナウンス。 - 今後3か月以内にGPT-4.5は利用不可能になる見込み。
- GPT-4.1がGPT-4.5と同等以上の性能を示したケースが多く、またGPUリソースを確保する必要があるための決断です。
少々寂しい気もありますが、モデルの最適化とGPUリソースのバランスを考えると、合理的な判断なのでしょう。
パートナー事例:Windsurfにおける先行導入

発表会の最後には、ゲストとしてWindsurf社のCEO兼創業者・Varun氏が登壇。Windsurfは「エージェンティック(Agentic)コーディングIDE」の主要プロバイダの一つであり、GPT-4.1をいち早く導入してその効果を検証しています。
Windsurfの評価ポイント
- 同社独自のSWE-benchに似たベンチマークでテストした結果、GPT-4.1はGPT-4o比で60%の性能向上を示した。
- ユーザーの利用体験で重要なのは「最終解が出せるか」だけでなく、「いかにスムーズにインタラクションできるか」。「不要なファイルを読もうとする」「不要なファイルを勝手に書き換える」のような“変な動き”が、他のモデルと比較してGPT-4.1では大幅に減少している。
- 不要ファイルの読み込みは40%減。
- 不要ファイルの変更は70%減。
- 出力が冗長になる割合も50%減少。病的なほど長ったらしい回答が減ったとのことで、扱いやすさが格段に増したという印象だそうです。
Windsurfでの無料提供施策
Windsurf社では、この圧倒的なパフォーマンスに感銘を受け、1週間限定で無料開放し、その後も大幅に割引された価格で提供するとコメント。先行してユーザーがGPT-4.1の性能を試せるチャンスですね。CEO Kevin氏が「週末に8歳の息子さんと一緒にLEGO販売用のWebサイトをVibe Codingで作った」と語るなど、利用事例はじつにバラエティに富んでいるようです。
デモ紹介:簡単Webアプリから大規模ログ解析まで
発表会では、2つの主なデモンストレーションが行われました。
シングルファイルで完結するWebアプリ作成
OpenAI PlaygroundからGPT-4.1を呼び出し、「単一のPythonファイルでアプリを動かしたい」とシステムメッセージに指示を記述。すると数百行にわたるコードをまるごと一度に生成し、「大型テキストファイルをアップロードし、質問できるWebサイト」が完成するとのこと。
- 実際、Pythonファイル内でHTML/CSS/JSまでインライン生成。
- Flaskのような軽量フレームワークを利用して、アップロード機能や質問機能を実装。
ほぼコピペで動くので、そのままローカル実行が可能。
450,000トークンのNASAサーバーログ解析
次に、約45万トークンという大規模ログファイルを例に、「明らかに異質な1行が混じっているかどうか」を検出させるデモ。結果、GPT-4.1はファイルの中から誤挿入された行を迅速に特定。これまでのモデルでは不可能だった超大規模コンテキストを取り扱えたことを印象づけました。
- 450,000トークンというスケールは、旧モデル(128kトークン制限)をはるかに超える。
- スキャン速度や処理の安定性にも注目が集まり、デモではスムーズに発話が出てきた点が高評価。
今後の展望とFine-tuningの可能性
今回発表されたGPT-4.1ファミリーは、すでにAPIで利用可能とのこと。また、細かいパーソナライズを行いたい開発者向けに、Fine-tuning機能もリリース済みです(GPT-4.1およびGPT-4.1 miniが先行して対応し、nanoは後日対応予定)。
- 「自社のドキュメントや製品情報に特化したモデルを育てたい」
- 「業種固有の専門用語や特殊フォーマット要件を盛り込みたい」
こうしたニーズを持つ方にとって、Fine-tuningは非常に有力な選択肢になるでしょう。一方で、ベースモデルがここまで高性能化すると、追加の調整がほとんど要らない場合も多いかもしれません。いずれにせよ、選択の幅が広がったことで、より一層ユーザー特化のソリューションを作りやすくなるはずです。
まとめ
以上がOpenAIの最新モデル「GPT-4.1」シリーズ発表会の全体像です。ポイントを整理すると:
- 開発者向けに最適化された新世代モデル:GPT-4.1, GPT-4.1 mini, GPT-4.1 nano
- ロングコンテキスト100万トークンを全モデルでサポート(追加料金なし)
- コーディング能力、指示追従性能、多言語対応、マルチモーダル処理が総合的に向上
- 価格は従来モデルよりも安価(例:GPT-4.1で26%減、nanoはさらに安い)
- GPT-4.5はGPUリソース確保のため3か月以内に廃止予定
- 大規模ログ解析の一括処理、Diff形式やフロントエンド生成など実用的シーンが充実
- Fine-tuningも解禁され、今後のエコシステム拡充に期待大
特に、100万トークンという超ロングコンテキストに伴う恩恵は計り知れません。膨大なマニュアルや履歴、ログ、研究データなどをまるごとモデルに読み込ませられるのは、多くの企業や研究機関にとって革命的とも言えるでしょう。早速、私たちTANREN株式会社でもこの動向を注視しながら、パフォーマンス評価アプリの機能改善に活かせないか検討を進めていく所存です。
最後に、OpenAIからは「開発者の皆様、引き続きフィードバックをお願いします」とのメッセージがありました。オプトインでログを共有してくれた開発者コミュニティの力によって、このような驚異的モデルが実現しているそうです。もし皆さんもGPT-4.1をお試しになる際には、ぜひOpenAIや私たちにもご意見をお寄せください。
桜木美佳のひと言
「なんだかんだでモデルの進化は止まりません。GPT-4.1 nano級のサクサク&激安AIが今後当たり前になるとしたら、アプリ開発のスピードはさらに上がりそうですね。モリモリ仕事こなして早く帰りたい、という方には朗報ではないでしょうか?」
これからも、TANRENでは最新情報をキャッチアップしながら、皆さんのビジネスや開発をサポートしていきます。引き続きよろしくお願いいたします!




